Neural networks
 Fig. 1: A picture of a bunch of neurons |
Neural networks represent an approach significantly different from the symbolic one looked at previously, and they are considered to be part of what we have called structural or connectionist AI. The basic idea is to reproduce intelligence and learning in particular by simulating the neural structure of an animal brain on the computer.
The idea of building an intelligent machine starting from artificial neurons can be traced back to the origins of AI, and some results were already
obtained by McCulloch and Pitts in 1943 when the first neural model was born; in time these were further developed by other researchers. In 1962
Rosenblatt proposed another neuron model, the
«perceptron![]() »,
capable of learning through examples.
»,
capable of learning through examples.
A perceptron reproduces a neuron's activity by making a weighed sum of its inputs and emitting in output 1 if their sum is above a modifiable threshold value, or 0 if otherwise. A learning process of this kind implies the modification of the value of the weights. The great enthusiasm initially shown for this approach suffered a harsh decline a few years later, when Minsky and Papert underlined the perceptron's great limitations in learning.
In more recent times new architectures, called connectionist, of neural networks were proposed, no longer subject to the theoretical limitations of the perceptron, making use of powerful learning algorithms.
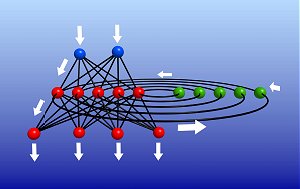
Fig. 2: A recurrent neural network, characterized by feedback connections.
Neural networks' learning paradigms can be divided into three main classes:
- Supervised learning through examples where a teacher provides the network with the answers the neurons should produce after the learning phase;
- Unsupervised learning: through internal competition, neurons specialize in discriminating stimulations produced upon entry;
- Reinforcement learning: the network is provided with only a qualitative answer according to the correctness of its answer.
Neural networks are more suitable for tasks implying classification and perception of low level concepts, albeit perhaps technically arduous, as, for example, recognition of spoken language, process control and image recognition, while conceptually complex problems, such as planning, diagnosis and projecting, remain the dominion of symbolic AI.
Below you will find a Java applet that simulates the learning phase of a neural network (see Artificial Neural Network Lab on the Web).